| build | ||
| ctest | ||
| data | ||
| execenv | ||
| nim | ||
| rust | ||
| words@04f5cdd221 | ||
| .gitignore | ||
| .gitmodules | ||
| CMakeLists.txt | ||
| Makefile | ||
| README.md | ||
| wikimedia_wikipedia | ||
Background & Methodoly
Inspiration
(note, if you wish to execute and compile the data yourself. go to ./execenv. There is a readme in there for that)
. If the findings were reproducible, It would be possible to identify languages using a straightforward method, of simply comparing character frequencies. This method has been used to identify cryptographic passphrase's language, and deduce the language of a given cipher block.
Does it hold up?
Well, yes, but vowels are pretty consistent across language families. If you omit vowels, languages become pretty distinct.
-- ES V DE No Vowels
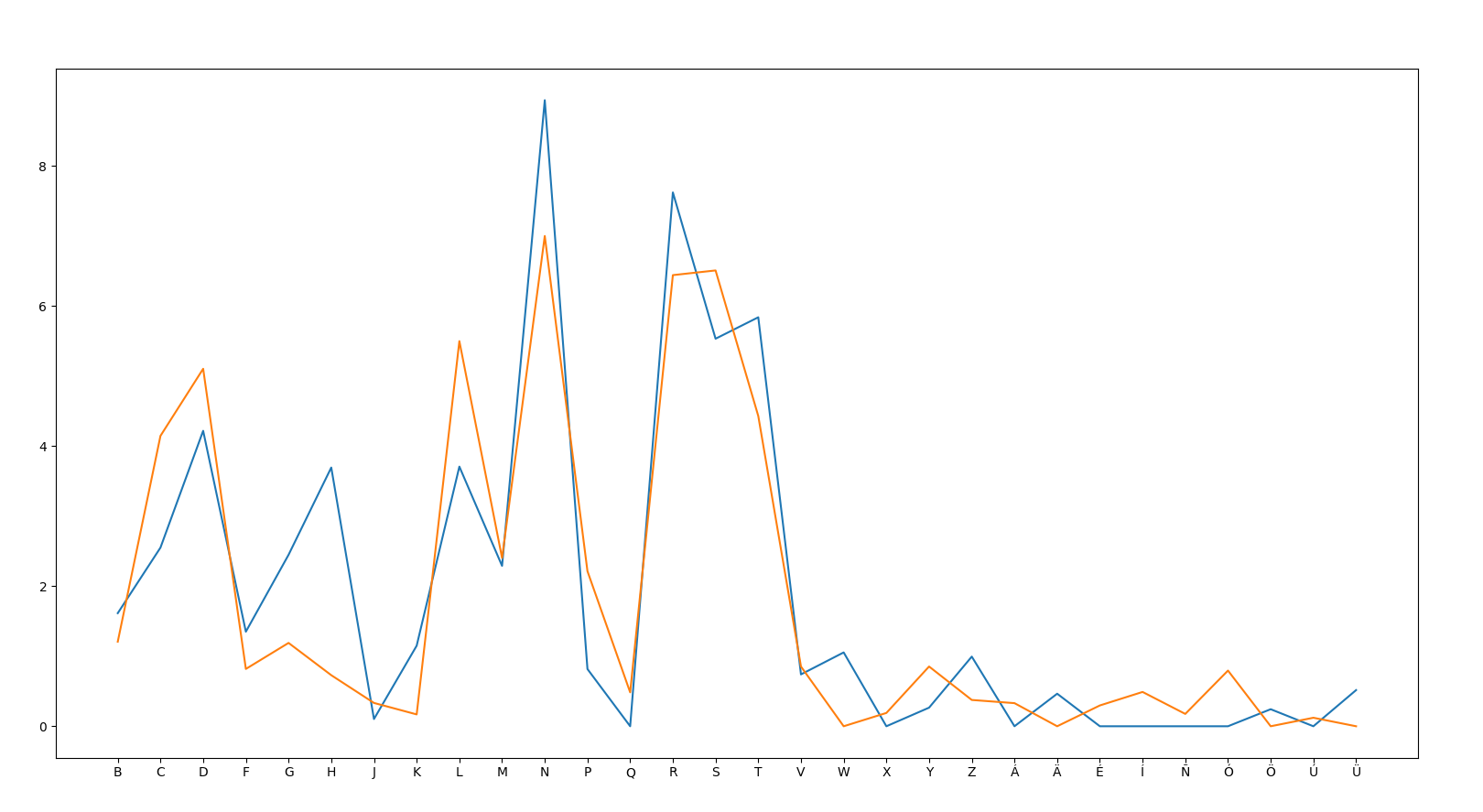
-- ES V DE With Vowels
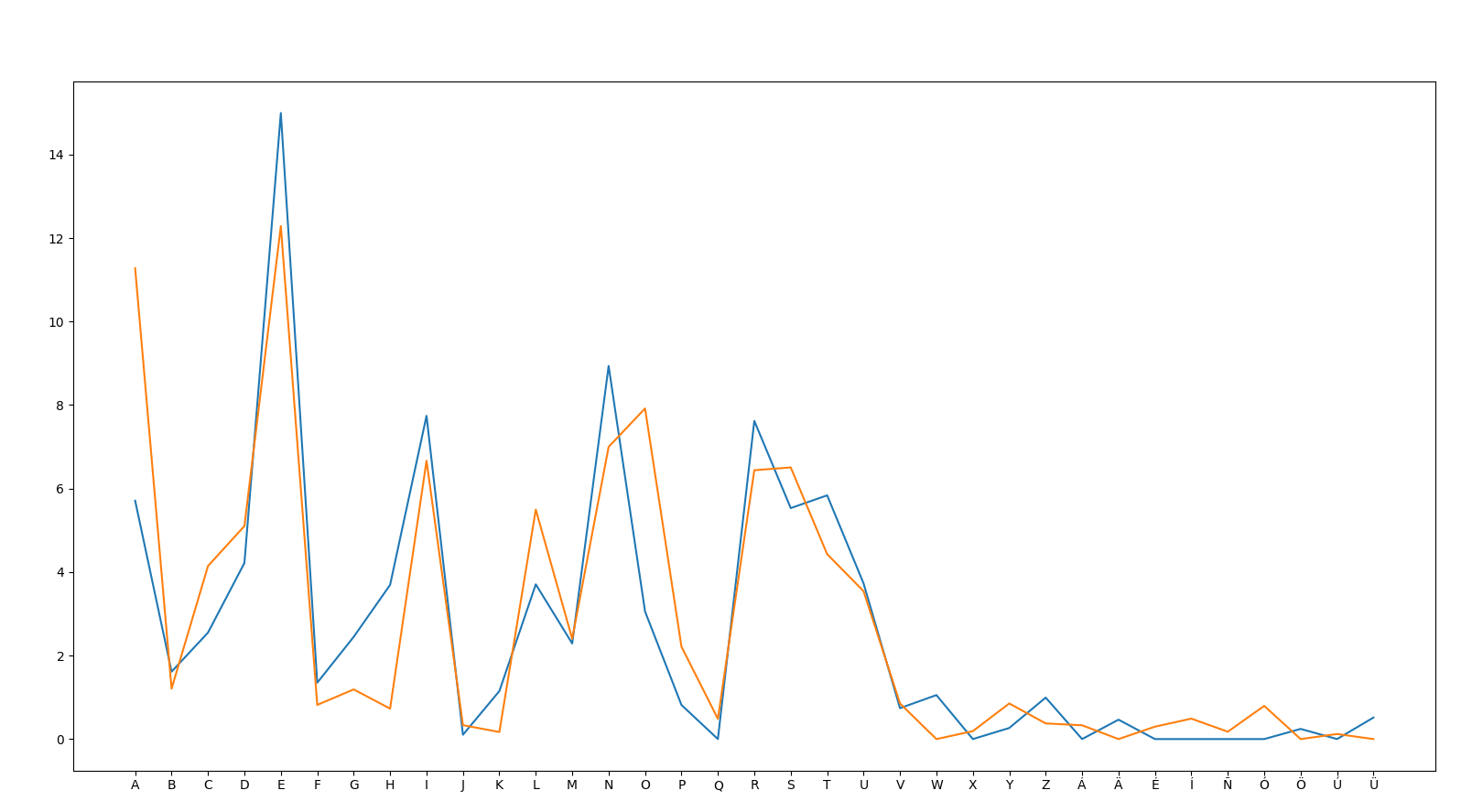
- There is a much greater correlation if AEIOU is included
-- ES V PT
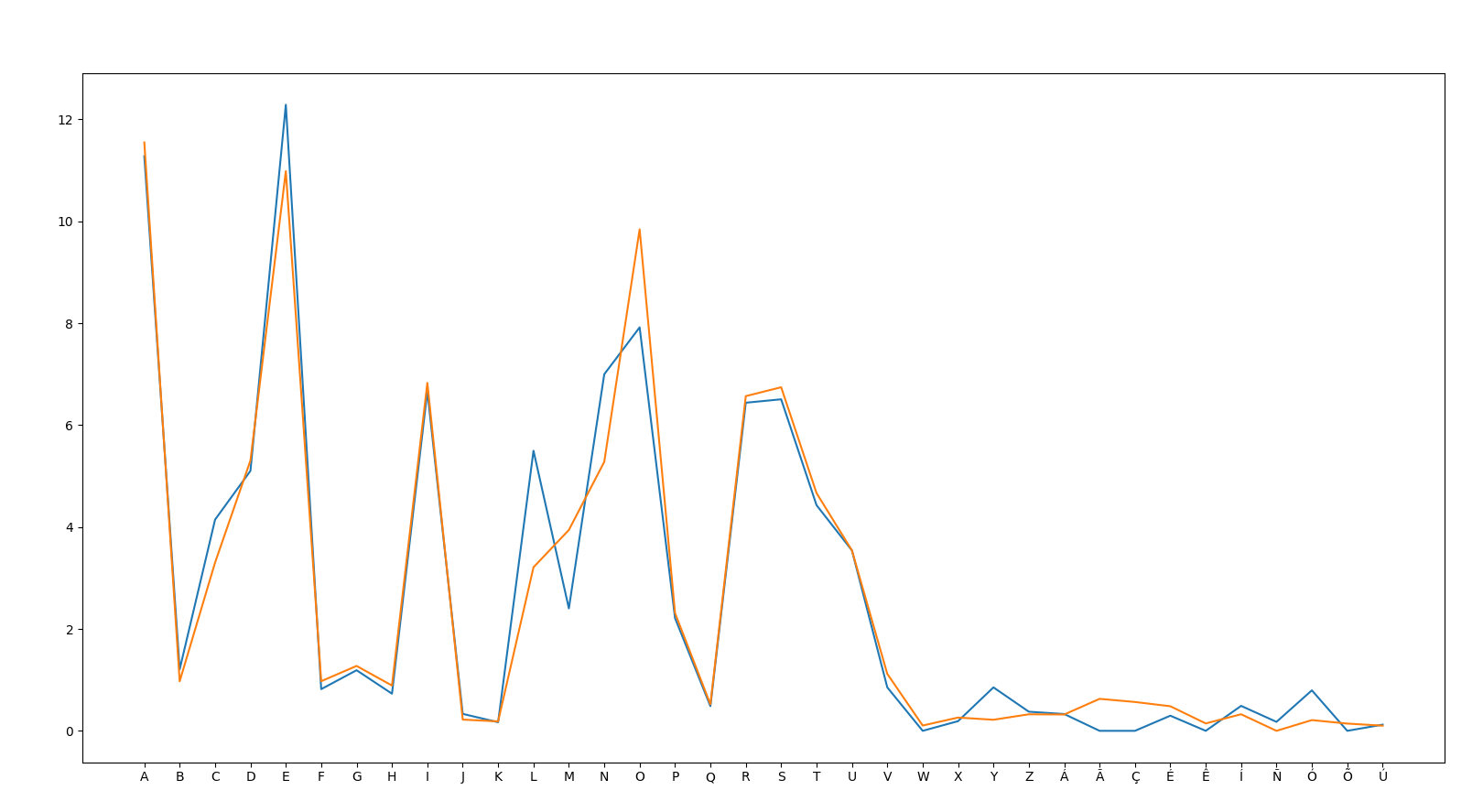
- As you can see, Spanish and Portugese being so closely related makes them hard to tell apart.
-- PT V ID V VI
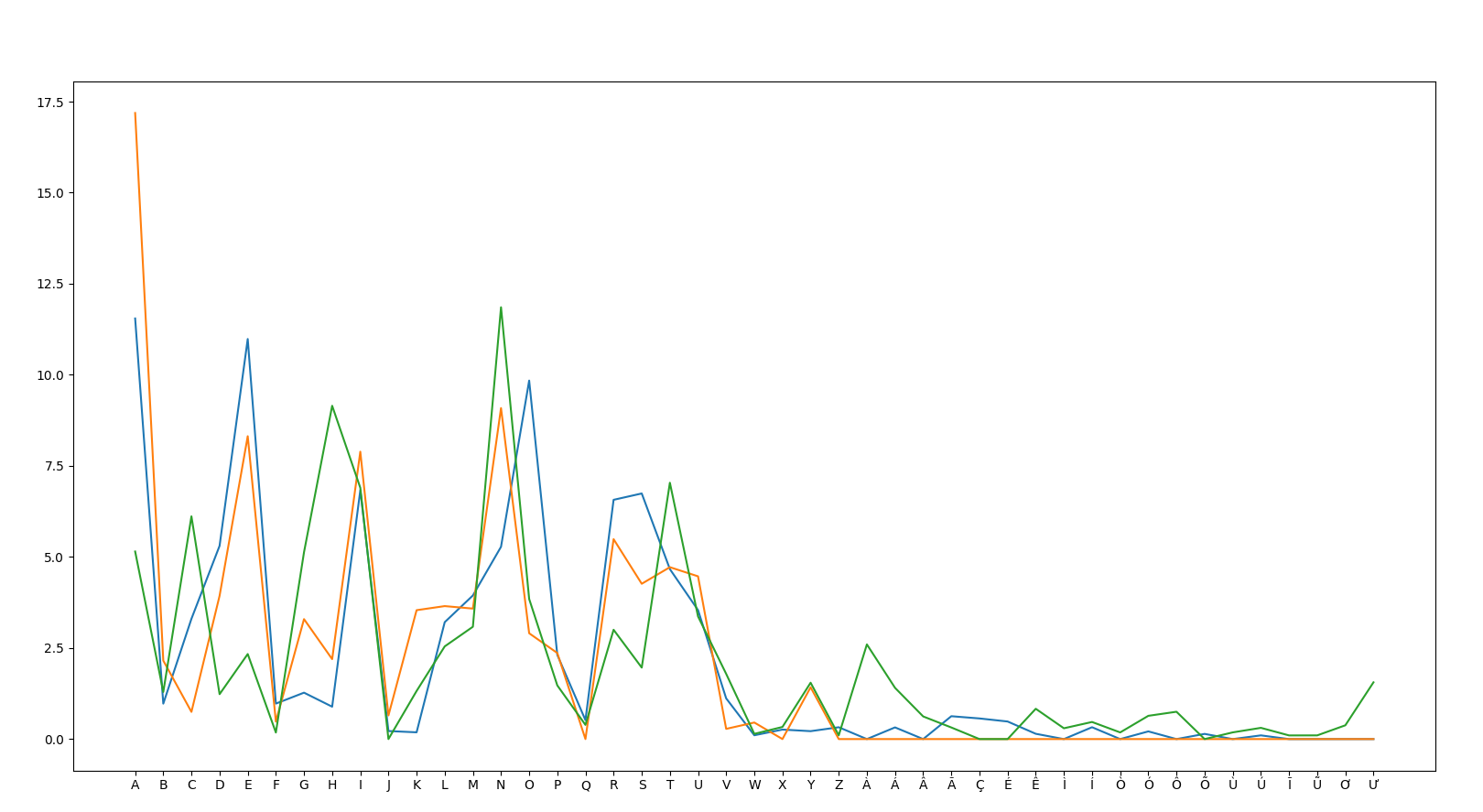
- The correlation is much weaker across language families, even within the same script
Orthography is a cultural thing, and sometimes, it does not well reflect the language it is made to represent. Languages which are closely linked culturally and historically become hard to take apart, as with our example of Portuguese and Spanish. Two Indo-European languages written in Latin will look similar as well, especially if you include A E I O U. However, orthography seems to clump and cluster around language families/groups if they are using the same writing system. They are not always wholly distinct for your average sample.
To overcome this limitation, a machine learning-driven algorithm is implemented to increase the accuracy rate. This helps similar languages with the same writing system.
Here is a comparison of output, run between the following languages: English, French, Indonesian, and Swahili.
- En
- With Word assistance
- Correct: 19879
- Incorrect: 1282
- Incorrect by language:
- id: 388
- fr: 859
- sw: 35
- En
- Without Word assistance
- Correct: 19743
- Incorrect: 1467
- Incorrect by language
- id: 439 (13% increase)
- fr: 990 (15.26% increase)
- sw: 38 (8% increase)
French makes up an equally large portion of English words to Greek and Latin. And, French has a very deep connection with English. So it makes sense that, there is a 15% increase in mistakes when there is no word layer.
It does hold up in a general sense, ~80% of the time.
The process
All data is sourced from Wikipedia. The data is scraped in 3 parts.
-
Every single word in a given Wikipedia.
-
Every single character in every single word in every single Wikipedia, counted.
-
Samples from every single Wikipedia article, used to test and to create word scores.
This data is serialized and stored in ..data/ in JSON files. These files are read at compile time, and pre-processed, for speed purposes.
This data is used to make a model of character occurrences for each language.
For languages, where possible, a second dataset is created using an algorithm, a set of words which are both most common and most unique to a given language. The purpose and effects were detailed in the above passage.
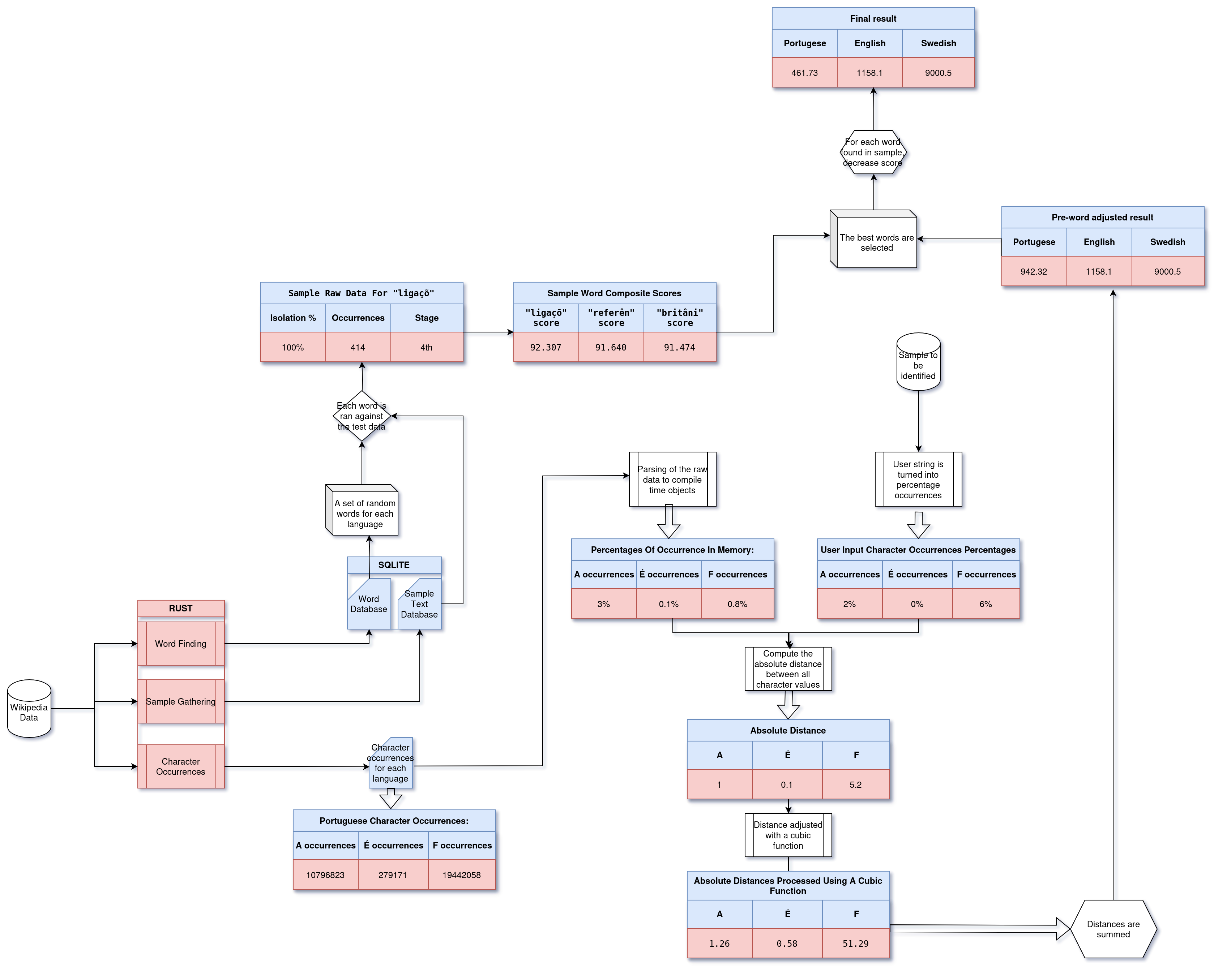
Character occurrences
A slope is created, where, each character in a language is converted to a percentage of the total found. For example, if a language had 1000 characters in it, and 1 of them was "a", "a" = 0.1. The top 0.1% of characters are counted as "in this language" and, the others are discarded. The same process is done for any given sample string to identify.
The next step is for each character, is to get the absolute distance between each character.
If a character is in the string sample but not but not in the reference (as it didn't pass 0.1%), then the distance is defaulted to 10.
For example, a sample has a "w" occurrence rate of 2% and the sample language is 0.5%, the distance is 1.5. This distance is then processed through a cubic function. That 1.5 is now 1.11.
As of writing, the function looks like this:
0.3*(Distance-0.33)^3+0.56
This function penalizes large distances and rewards small distances.
The distances are accumulated, and then summed, and the language with the smallest distance total is the most likely.
Note: The algorithm takes as a parameter the languages you're testing for. The more languages, the more languages, the more calculations.
Words
After character occurrences are chosen, each word for each language selected is iterated through. If this word is found in the sample, the score is decreased by *= 0.7 as of writing.
Words algorithm
For each language, words and word segments (split from "root-words") are chosen from the words database, and compared against all Wikipedia samples. Two variables are created from this:
-
Isolation: The percentage of a given word's occurrence in the target language versus, the non-target languages
-
Occurrences: The total Occurrences / Number of Samples tested against
A composite score is then generated from these two variables. The equation for this score is as follows:
Where:
i = isolation percentage
o = total word occurrence
s = total samples tested against
p = (i/10)*2
ops = o/s
q = (ops/7)+1.0
x = q^i
s = 4.9*(1.03^x))+-2.8
The top n best scoring words are outputted and stored in data/mostCommonWords.json
Words are tested in 4 stages, and testing is stopped depending on how good the words are performing. After each state, 50% of the words are stopped. Each stage is 25% of total samples. Only 0.125% of all words are tested against the entire database.
For 1000 words:
25%: 1000 words
50% 500 words
75% 250 words
100% 125 words
This is for optimization purposes.
Flowchart
Paramaters
Thus header can be found in build/
void zipfs_language_detector(
//The languages you wish to detect for. Given in lowercase Wikipedia form
// e.g ja for Japanese, sv for Swedish, en for English
char** languages,
//The total number of languages
uint64_t languages_count,
//The sample you wish to test
char* input_string,
//Pointer for if it is successful or not
bool* successful,
//The amount of languages in the result. Should be equal to languages_count
//But isn't always in case of an exception
uint64_t* length_output,
//The result scores. e.g 900.1, 2291.4, etc. In order of the result languages
float** result_buffer_float,
//The resulting languages, in order of most to least likely
char*** result
//The bottom two params make a table. e.g "en" : 1000.5
);